|
由上图可知,运行程序后我们发现了一些提供隐藏服务的服务器IP地址,它们分别位于法国、德国和荷兰。 可以发现,在连接的中继回路的第一个IP地址总是相同的。这是Tor的正常操作。连接的中继回路中的第一个节点通常被称为“入口节点/路由器”。它是一个快速且稳定的节点,并且将会在我们的中继回路中维持两到三个月,用来抵挡破解匿名攻击。其余的中继会在我们每次访问新网站时改变,这些中继会一起提供完整的隐私保护。 在这里,我们使用爬虫来进行暗网的情报收集。在一般爬虫程序的开头加入几行代码,同时保持Tor浏览器的开启,根据上文所收集的Tor匿名网络的域名,就能自动抓取这些网站的数据了。 下图显示了使用爬虫程序抓取某暗网论坛数据时主机对外所显示的IP地址。可见我们的公网IP已变为某个Tor匿名网络的出口节点的IP,其地址位于德国柏林: 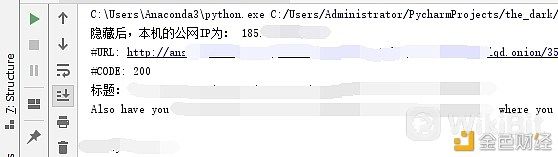 针对不同的暗网数据类型,如暗网市场、暗网论坛,应设计不同的爬虫框架。 在比特币转账追踪中,若某个比特币地址在暗网中(如论坛)也出现了,那么我们就可以根据它所在页面的信息来为它打上标签,并进一步根据相关信息尝试将该比特币地址与实体相关联,这就涉及到了暗网的情报分析。 5、对所收集的暗网情报进行分析[9],[13] 首先,对主体文本数据进行有效性判断。 在获取的正文文本中,有些文本是无效的,会增加工作量并妨碍文本分类的速度,因此如下的文本应标记成无效隐藏服务:(1)网页正文文本内容过短,很难对网页隐藏服务进行区分类别,应视为无效文本;(2)隐藏服务内容是网页服务器的默认启动页,无法区分暗网隐藏服务内容的默认启动页也视为无效;(3)网页已经无法打开的更不可能作为文本分类的依据。 其次,对数据内容进行处理。 为了躲避执法人员的调查与追踪,暗网数据内容存在着单词拼写错误、标点符号杂乱、非英文的标准字符多以及大小写混乱等问题,这些问题严重影响分类准确率。因此需要对数据内容进行相应的处理。 例如,使用Python的langdetect来识别正文语言,大多数隐藏的网页使用英语进行交流,有些则使用俄语或德语以及汉语,这里主要对英文网站进行分析;使用BeautifulSoup来删除复杂的非标准的特征字符;使用正则表达式来删除没有价值的简单标点符号;使用pyenchant来对英文单词进行拼写纠错;使用nltk库的SnowballStemmer提取英文词干;使用nltk库的WordNetLemmatizer进行英文词性还原;以及进行大小写转换,去掉像“in”、“an”等没有实际意义的助词、介词等,只保留对分类具有帮助的动词和名词。 (责任编辑:admin) |